Big Data > Spark > d. Kubernetes
Kubernetes
Kubernetes is a powerful, open-source container orchestration system that automates the deployment, scaling, and management of containerized applications. Originally developed by Google and now maintained by the Cloud Native Computing Foundation (CNCF), Kubernetes is widely used in modern cloud-native architectures. Since Apache Spark 2.3, Kubernetes has been supported as a native cluster manager for running Spark workloads in containers.
Kubernetes as a Spark Cluster Manager
In a Spark-on-Kubernetes setup, Spark applications are packaged into Docker containers and run on a Kubernetes cluster. Kubernetes plays the role of a cluster manager, similar to YARN or Mesos, managing the life cycle of Spark driver and executor processes as pods.
A Spark application in Kubernetes consists of:
- A driver pod: This is where the Spark driver program runs. It handles the application logic and coordinates the execution of tasks.
- One or more executor pods: These pods execute tasks assigned by the driver and handle the actual data processing.
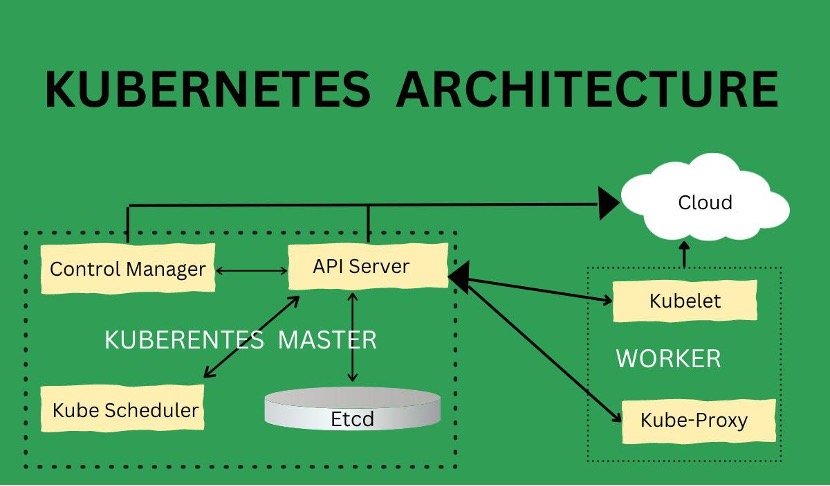
Key Components of Kubernetes for Spark:
- Kube-API Server: Acts as the central control plane component, receiving commands (e.g., from spark-submit) and managing application state.
- Scheduler: Places the driver and executor pods on appropriate nodes based on available resources.
- Kubelet: An agent running on each worker node that ensures containers (pods) are running as expected.
- etcd: Stores cluster configuration and state data.
- Controller Manager: Maintains the desired state of the cluster, such as ensuring a certain number of pods are running.
How Spark Submits a Job on Kubernetes
- A user submits a Spark job using the spark-submit command with Kubernetes as the cluster manager.
- The Spark driver is launched in a pod on the Kubernetes cluster.
- The driver requests executor pods from the Kubernetes scheduler based on the application's needs.
- Kubernetes launches the executor pods, which then connect back to the driver.
- The driver coordinates task execution across executors until the job completes.
Benefits of Using Kubernetes for Spark
- Containerized Deployment: Spark runs inside Docker containers, ensuring consistency and easy deployment across environments.
- Dynamic Scaling: Kubernetes can automatically scale executors up or down based on workload.
- High Availability and Fault Tolerance: Built-in mechanisms like pod health checks and restarts enhance Spark application reliability.
- Multi-tenancy and Resource Isolation: Kubernetes namespaces and resource quotas allow for better sharing and isolation in multi-user environments.
- Cloud-Native Integration: Kubernetes works seamlessly with cloud platforms (AWS EKS, GCP GKE, Azure AKS), making it ideal for deploying Spark in cloud environments.
Feedback
ABOUT
Statlearner
Statlearner STUDY
Statlearner